7 การแสดงการแจกแจง : ฮิสโตแกรมและ density plots
แปล Data Visualization ขั้นพื้นฐาน Claus O. Wilke
บ่อยครั้งเราอาจอยากเข้าใจว่าข้อมูลมีการกระจายตัวอย่างไร ตัวอย่างเช่น ชุดข้อมูลไททานิคที่เป็นชุดข้อมูลที่เราพูดถึงในบทที่ 6 มีประมาณ 1300 คน บน Titanic (ไม่นับลูกเรือ) และเราได้รับรายงานอายุของ 756 คนที่เราต้องการทราบจำนวนที่มีอยู่บนไททานิคว่ามีหลาย ๆ คนที่เป็นผู้ใหญ่ เราเรียกเปอร์เซ็นต์ที่แตกต่างกันหลายครั้งในหลายประเทศ
7.1 การแสดงค่ามิติเดี่ยว
เราสามารถแสดงถึงการกระจายตัวของอายุของผู้โดยสาร โดยการจัดกลุ่มผู้โดยสารทั้งหมดเป็นกลุ่มที่มีอายุเท่ากันและนับจำนวนผู้โดยสารในแต่ละกลุ่ม วิธีการนี้ให้ผลลัพธ์ในตารางเช่นตาราง 7.1

เราสามารถมองเห็นตารางนี้โดยการวาดสี่เหลี่ยมที่มีความสูงตรงกับจำนวนและความกว้างสอดคล้องกับความกว้างของช่วงอายุ (รูปที่ 7.1) การสร้างภาพข้อมูลนั้นเรียกว่าฮิสโตแกรม (ช่วงทั้งหมดจะต้องมีความกว้างเท่ากันเพื่อให้การสร้างภาพข้อมูลเป็นฮิสโตแกรมที่ถูกต้อง)

เนื่องจากฮิสโทแกรมถูกสร้างขึ้นโดยการผูกข้อมูลลักษณะที่ปรากฏที่แน่นอน จึงขึ้นอยู่กับการเลือกความกว้างของช่วง โปรแกรมสร้างภาพส่วนใหญ่ที่สร้างฮิสโตแกรมจะเลือกความกว้างของช่วงโดยค่าเริ่มต้น แต่โอกาสที่ความกว้างของช่วงข้อมูลนั้นไม่เหมาะสมที่สุดสำหรับฮิสโตแกรมใด ๆ ที่คุณต้องการ ดังนั้นจึงเป็นเรื่องสำคัญอย่างยิ่งที่จะต้องลองความกว้างของช่วงที่แตกต่างกันเสมอเพื่อตรวจสอบว่าฮิสโตแกรมที่ได้นั้นสะท้อนข้อมูลที่ถูกต้อง โดยทั่วไปหากความกว้างของช่วงข้อมูลมีขนาดเล็กเกินไปฮิสโตแกรมจะสูงเกินไปและไม่ว่างทางสายตาและแนวโน้มหลักในข้อมูลอาจถูกบดบัง ในทางกลับกันหากความกว้างของช่วงที่มีขนาดใหญ่เกินไปคุณสมบัติที่เล็กลงในการกระจายข้อมูลเช่นการช่วงประมาณ 10 ปีอาจหายไป
สำหรับการกระจายอายุของผู้โดยสารไททานิคเราจะเห็นได้ว่าความกว้างของช่วงหนึ่งปีนั้นเล็กเกินไปและความกว้างของช่วงสิบห้าปีนั้นใหญ่เกินไปในขณะที่ความกว้างของช่วงระหว่างสามถึงห้าปีเหมาะสมที่สุด

เมื่อสร้างฮิสโตแกรมสำรวจความกว้างของช่วงหลาย ๆ ครั้งเสมอ
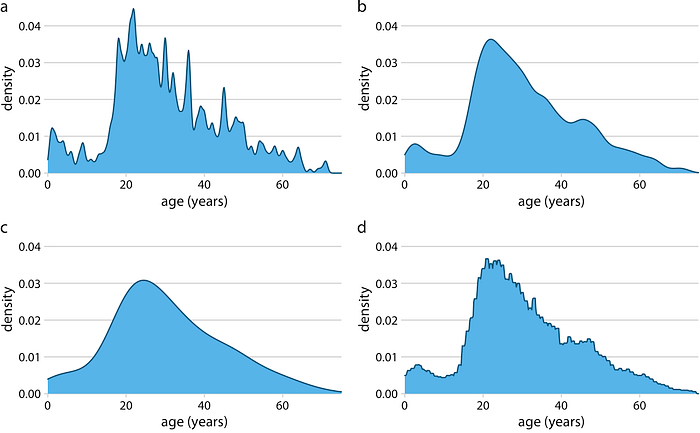
ฮิสโทแกรมเป็นตัวเลือกในการแสดงข้อมูลที่ได้รับความนิยมตั้งแต่ต้นศตวรรษที่ 18 ส่วนหนึ่งเป็นเพราะฮิสโทแกรมสร้างขึ้นได้ง่ายด้วยมือ ในปัจจุบันเนื่องจากพลังการประมวลผลที่กว้างขวางได้กลายเป็นอุปกรณ์ที่มีอยู่ในชีวิตประจำวันเช่นแล็ปท็อปและโทรศัพท์มือถือเราเห็นว่ามันถูกแทนที่ด้วยค่ามิติเดี่ยว ในพล็อตตัวแปลมิติเดียว เราพยายามที่จะเห็นภาพการกระจายความน่าจะเป็นพื้นฐานของข้อมูลโดยการวาดเส้นโค้งต่อเนื่องที่เหมาะสม (รูปที่ 7.3) เส้นโค้งนี้จะต้องมีการประมาณจากข้อมูลและวิธีการที่ใช้กันมากที่สุดสำหรับขั้นตอนการประเมินนี้เรียกว่าการประมาณ kernel density ในการประมาณkernel densityเราวาดเส้นโค้งอย่างต่อเนื่อง (เคอร์เนล) ที่มีความกว้างขนาดเล็ก (ควบคุมโดยพารามิเตอร์ที่เรียกว่าแบนด์วิดท์) ที่ตำแหน่งของจุดข้อมูลแต่ละจุดจากนั้นเราจะเพิ่มเส้นโค้งเหล่านี้ทั้งหมด เคอร์เนลที่ใช้กันอย่างแพร่หลายที่สุดคือเคอร์เนลเกาส์เซียน (เช่น Gaussian bell curve) แต่มีตัวเลือกอื่น ๆ อีกมากมาย

เช่นเดียวกับกรณีที่มีฮิสโตแกรมลักษณะที่ปรากฏทางภาพที่แน่นอนของ density plot ขึ้นอยู่กับตัวเลือก kernel และ bandwidth(รูปที่ 7.4) พารามิเตอร์แบนด์วิดธ์ทำงานคล้ายกับความกว้างของช่องเก็บในฮิสโทแกรม หากแบนด์วิดท์เล็กเกินไปการประมาณความหนาแน่นอาจสูงเกินไปและยุ่งมากจนมองเห็นไม่ได้และแนวโน้มหลักในข้อมูลอาจถูกบดบัง ในทางกลับกันถ้าแบนด์วิดท์มีขนาดใหญ่เกินไปคุณสมบัติที่เล็กลงในการกระจายข้อมูลอาจหายไป นอกจากนี้การเลือกเคอร์เนลมีผลต่อรูปร่างของเส้นโค้งความหนาแน่น ตัวอย่างเช่นเคอร์เนลแบบเกาส์เซียนจะมีแนวโน้มที่จะสร้างการประมาณความหนาแน่นที่มีลักษณะแบบเกาส์เซียนพร้อมด้วยคุณสมบัติที่นุ่มนวลและก้อย ในทางตรงกันข้ามเคอร์เนลรูปสี่เหลี่ยมผืนผ้าสามารถสร้างลักษณะที่ปรากฏของขั้นตอนในกราฟเส้นโค้งความหนาแน่น (รูปที่ 7.4d) โดยทั่วไปยิ่งมีจุดข้อมูลอยู่ในชุดข้อมูลมากเท่าใดการเลือกเคอร์เนลก็ยิ่งน้อยลงเท่านั้น ดังนั้นพล็อตความหนาแน่นจึงค่อนข้างน่าเชื่อถือและให้ข้อมูลสำหรับชุดข้อมูลขนาดใหญ่ แต่อาจทำให้เข้าใจผิดสำหรับชุดข้อมูลเพียงไม่กี่จุด
การประเมิน Kernel density มีหนึ่งหลุมพรางที่เราต้องระวัง: มีแนวโน้มที่จะสร้างลักษณะของข้อมูลที่ไม่มีอยู่โดยเฉพาะในส่วนท้าย ผลที่ตามมาคือการใช้การประมาณความหนาแน่นแบบไม่ประมาทสามารถนำไปสู่ตัวเลขที่สร้างข้อความไร้สาระได้อย่างง่ายดาย ตัวอย่างเช่นหากเราไม่ใส่ใจเราอาจสร้างภาพข้อมูลการกระจายอายุที่มีอายุเชิงลบ (รูปที่ 7.5)
ตรวจสอบเสมอว่าการประเมิน density ของคุณไม่ได้คาดการณ์การมีอยู่ของค่าข้อมูลไร้สาระ
ดังนั้นคุณควรใช้ฮิสโตแกรมหรือ density plot เพื่อแสดงภาพการแจกแจงหรือไม่? การอภิปรายในหัวข้อนี้ บางคนไม่ชอบ density plot และเชื่อว่ามักทำให้เข้าใจผิด คนอื่น ๆ ตระหนักว่าฮิสโทแกรมนั้นสามารถสร้างความเข้าใจผิดและทำให้เข้าใจผิดได้ ฉันคิดว่าตัวเลือกส่วนใหญ่เป็นเรื่องของรสนิยม แต่บางครั้งตัวเลือกตัวเลือกหนึ่งอย่างอื่นอาจสะท้อนถึงคุณลักษณะเฉพาะที่น่าสนใจของข้อมูลในมือ นอกจากนี้ยังมีความเป็นไปได้ที่จะไม่ใช้และแทนที่จะเลือกฟังก์ชัน density สะสมเชิงประจักษ์หรือแปลง q-q (บทที่ 8) ในที่สุดฉันเชื่อว่าการประเมิน density มีข้อได้เปรียบเหนือฮิสโทแกรมทันทีที่เราต้องการเห็นภาพการกระจายมากกว่าหนึ่งครั้งในแต่ละครั้ง (ดูหัวข้อถัดไป)
7.2 การแสดงข้อมูลหลายมิติและข้อมูลอนุกรมเวลา
ในหลายสถานการณ์เรามีหลายตัวแปลที่เราต้องการให้เห็นภาพพร้อมกัน ตัวอย่างเช่นสมมติว่าเราต้องการดูว่าอายุของผู้โดยสารไททานิคกระจายกันอย่างไรระหว่างผู้ชายกับผู้หญิง ผู้โดยสารชายและหญิงโดยทั่วไปมีอายุเท่ากันหรือว่าอายุต่างกันระหว่างเพศหรือไม่? กลยุทธ์การสร้างภาพข้อมูลที่ใช้โดยทั่วไปในกรณีนี้คือฮิสโตแกรมซ้อนที่เราวาดแท่งกราฟฮิสโตแกรมสำหรับผู้หญิงที่ด้านบนสุดของบาร์สำหรับผู้ชาย
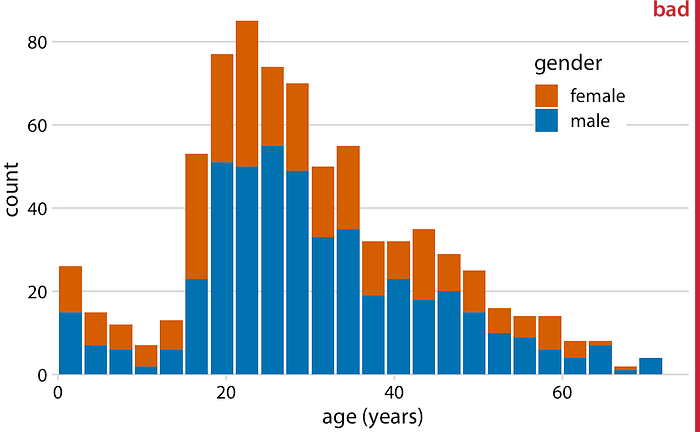
ในความคิดของฉันควรหลีกเลี่ยงการสร้างภาพข้อมูลประเภทนี้ มีปัญหาสำคัญสองประการที่นี่: ประการแรกจากการดูที่รูปมันไม่ชัดเจนเลยว่าบาร์เริ่มต้นตรงไหน มันเริ่มต้นที่การเปลี่ยนสีหรือพวกเขาตั้งใจที่จะเริ่มต้นที่ศูนย์? กล่าวอีกนัยหนึ่งมีผู้หญิงอายุ 25–20 ปีประมาณ 25–20 คนหรือเกือบ 80 คน (อดีตคือกรณี) ประการที่สองความสูงของบาร์สำหรับการนับเพศหญิงไม่สามารถเปรียบเทียบได้โดยตรงกับแต่ละอื่น ๆ เพราะแท่งทั้งหมดเริ่มต้นที่ความสูงที่แตกต่างกัน ตัวอย่างเช่นผู้ชายมีอายุมากกว่าผู้หญิงโดยเฉลี่ยและความจริงข้อนี้ไม่ปรากฏในภาพที่ 7.6
เราสามารถพยายามแก้ไขปัญหาเหล่านี้โดยเริ่มต้นที่บาร์ทั้งหมดที่ศูนย์และทำให้บาร์โปร่งใสบางส่วน (รูปที่ 7.7)
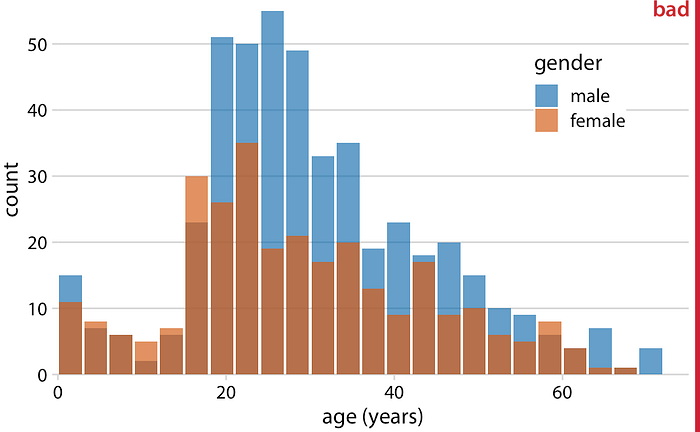
อย่างไรก็ตามวิธีนี้สร้างปัญหาใหม่ ขณะนี้ปรากฏว่ามีกลุ่มที่แตกต่างกันสามกลุ่มไม่ใช่แค่สองกลุ่มเท่านั้นและเรายังไม่แน่ใจว่าแต่ละแถบเริ่มต้นและสิ้นสุดที่ใด ฮิสโทแกรมที่ทับซ้อนกันไม่ทำงานได้ดีเนื่องจากแถบกึ่งโปร่งใสที่ลากมาจากด้านบนมีแนวโน้มที่จะไม่ดูเหมือนแถบกึ่งโปร่งใส แต่แทนที่จะเป็นแท่งที่มีสีแตกต่างกัน
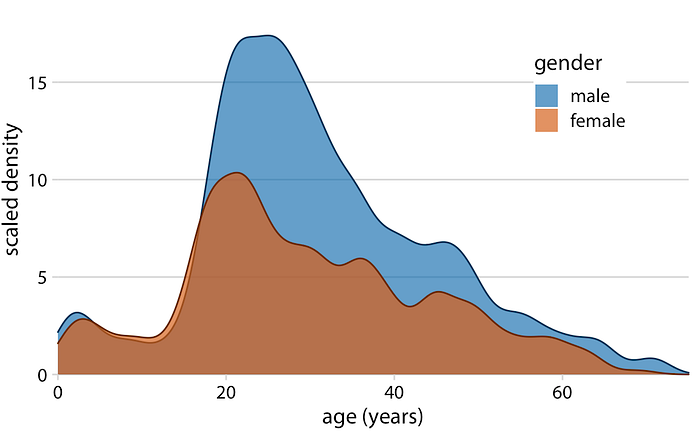
density plots ที่ทับซ้อนกันโดยทั่วไปจะไม่มีปัญหาที่ฮิสโทแกรมที่ทับซ้อนกันมีเนื่องจากเส้นความหนาแน่นต่อเนื่องช่วยให้การกระจายของดวงตาแยกกัน อย่างไรก็ตามสำหรับชุดข้อมูลนี้การแจกแจงอายุสำหรับผู้โดยสารชายและหญิงเกือบจะเหมือนกันจนถึงอายุ 17 แล้วแยกออกเพื่อให้การสร้างภาพข้อมูลยังไม่สมบูรณ์ (รูปที่ 7.8)
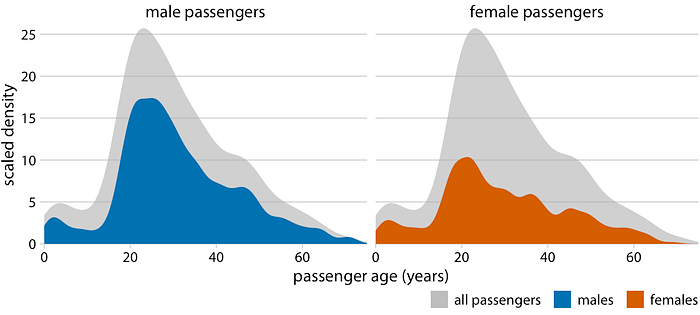
วิธีการแก้ปัญหาที่ใช้งานได้ดีสำหรับชุดข้อมูลนี้คือการแสดงการกระจายอายุของผู้โดยสารชายและหญิงแยกกันโดยแต่ละสัดส่วนจะเป็นสัดส่วนของการกระจายอายุโดยรวม (รูปที่ 7.9) การสร้างภาพข้อมูลนี้แสดงให้เห็นอย่างชัดเจนและชัดเจนว่ามีผู้หญิงน้อยกว่าผู้ชายในช่วงอายุ 20–50 ปีบนไททานิค
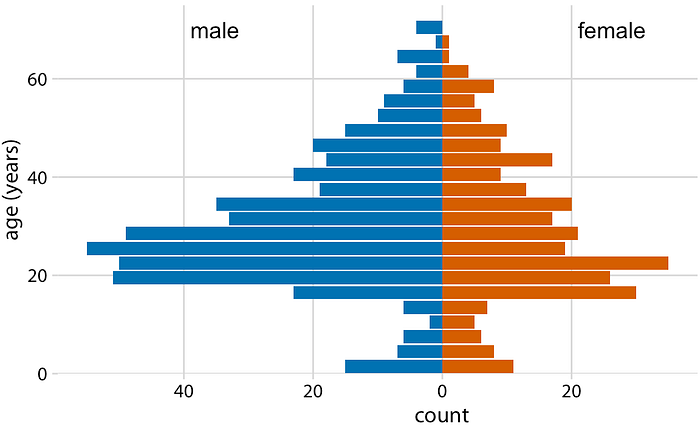
ในที่สุดเมื่อเราต้องการเห็นภาพการแจกแจงสองแบบเราก็สามารถสร้างฮิสโตแกรมแยกกันสองอันหมุนพวกมัน 90 องศาและมีแท่งในจุดฮิสโตแกรมหนึ่งจุดในทิศทางตรงกันข้ามของอีกอัน เคล็ดลับนี้ถูกใช้โดยทั่วไปเมื่อมองเห็นการแจกแจงอายุและพล็อตที่เกิดขึ้นมักเรียกว่าปิรามิดอายุ (รูปที่ 7.10)
ที่สำคัญเคล็ดลับนี้ใช้ไม่ได้เมื่อมีการแจกแจงมากกว่าสองรายการที่เราต้องการให้เห็นในเวลาเดียวกัน สำหรับการแจกแจงแบบหลายฮิสโทแกรมมีแนวโน้มที่จะเกิดความสับสนอย่างมากในขณะที่แผนการความหนาแน่นทำงานได้ดีตราบใดที่การแจกแจงค่อนข้างชัดเจน ตัวอย่างเช่นเมื่อต้องการให้เห็นภาพการกระจายตัวของเปอร์เซ็นต์ butterfat ระหว่างวัวจากวัวสี่สายพันธุ์ต่าง ๆ แปลงความหนาแน่นเป็นเรื่องปกติ (รูปที่ 7.11)
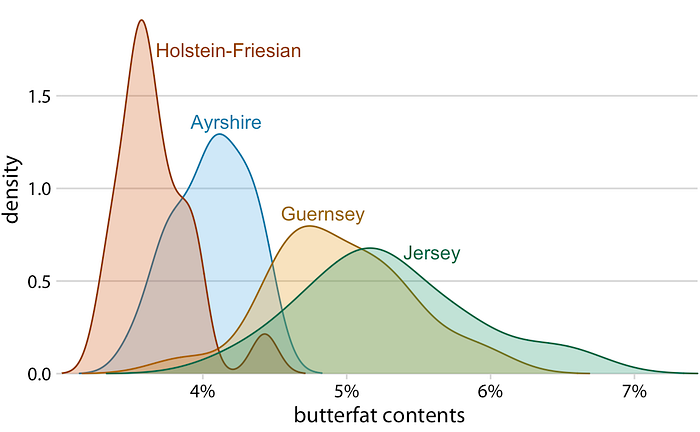
เพื่อให้เห็นภาพการกระจายหลาย ๆ ครั้งพร้อมกันkernel density plotsโดยทั่วไปจะทำงานได้ดีกว่าฮิสโตแกรม
อ่านบทอื่นๆได้ที่
2 .Visualizing data: การเเสดงข้อมูลอย่างมีศิลปะ
3 การแสดงข้อมูลในรูปพิกัดและแกน
7 การแสดงการแจกแจง: ฮิสโตแกรมและ density plots
8 การแสดงภาพการแจกแจง: ฟังก์ชันการแจกแปล แจงสะสมเชิงประจักษ์และq-q Plots
9 -การแสดงข้อมูลหลายตัวแปลในรูปเดี่ยว
11 การแสดงสัดส่วนข้อมูลที่ซ้อนกัน
12 การแสดงข้อมูลโดยเชื่อมโยงระหว่างตัวแปรเชิงปริมาณตั้งแต่สองตัวขึ้นไป
13 การแสดงข้อมูลอนุกรมเวลาและฟังก์ชั่นของตัวแปรอิสระ
15 การแสดงข้อมูลเชิงภูมิศาสตร์
17 หลักการแสดงข้อมูลที่เป็นสัดส่วน
18 การจัดการข้อมูลที่ซ้อนกันในการแสดงข้อมูล
19 ข้อผิดพลาดที่พบได้บ่อยเมื่อใช้สีแสดงข้อมูล
21 การแสดงข้อมูลหลายกราฟในรูปเดียว
22 ชื่อเรื่อง Captions และตาราง
23 การสร้างสมดุลระหว่างข้อมูลและบริบทแวดล้อมในการแสดงข้อมูล
24 การใช้ labels ที่มีขนาดใหญ่
25 หลีกเลียงการใช้เส้นในการสร้างกราฟ
